
Comparing Grok 3 with Claude, ChatGPT, Gemini, and DeepSeek: Which AI Model Reigns Supreme in 2025?

As of March 9, 2025, the AI landscape is buzzing with innovation, and xAI’s Grok 3 has taken center stage, claiming the title of the “smartest AI on Earth.” But how does it stack up against other leading models like Anthropic’s Claude, OpenAI’s ChatGPT, Google’s Gemini, and DeepSeek’s open-source offerings? In this blog post, we dive deep into the performance, capabilities, costs, and use cases of these AI models, drawing on benchmark data, web insights, and real-world applications to help you decide which one suits your needs best.
Performance Analysis: Grok 3 Takes the Lead
Grok 3, launched by xAI on February 18, 2025, has made headlines by becoming the first model to break a 1400 score on Chatbot Arena (LMSYS), outpacing competitors like Gemini-2.0-Flash-Thinking-Exp-01–21 (1384) and ChatGPT-4o-latest (1377). This score reflects its dominance in user preference across categories such as math, science, coding, and creative writing, with a focus on reasoning, speed, and honesty.
Math (AIME): Grok 3 scored an impressive 95.8% on the AIME 2024 benchmark, surpassing OpenAI’s o1 model, which achieved up to 93% with advanced techniques. Specific scores for Claude, Gemini, and DeepSeek were not readily available, but Grok 3’s performance suggests it’s a leader in mathematical reasoning.
Science (GPQA): In the GPQA main set, Grok 3 achieved a remarkable 84.6%, far exceeding Claude 3.5 Sonnet (67.2%) and GPT-4 (39%). For the more challenging GPQA Diamond set, DeepSeek-R1 scored 71.5%, Claude 3.5 Sonnet 59.4%, and GPT-4o 53.6%, indicating Grok 3 likely maintains its edge here, though exact Diamond scores for Grok 3 were not disclosed.
Coding (LiveCodeBench): Grok 3 scored 79.4% on LiveCodeBench, showcasing its prowess in code generation and repair. While Claude’s specific LiveCodeBench score is unavailable, its predecessor, Claude 3.5 Sonnet, is known for strong coding performance (e.g., 92.0% on HumanEval). DeepSeek-R1 also performs well in coding, with scores like 57.2% on LiveCodeBench for related models, but it falls short of Grok 3’s benchmark dominance.
Here’s a quick snapshot of key benchmark scores:
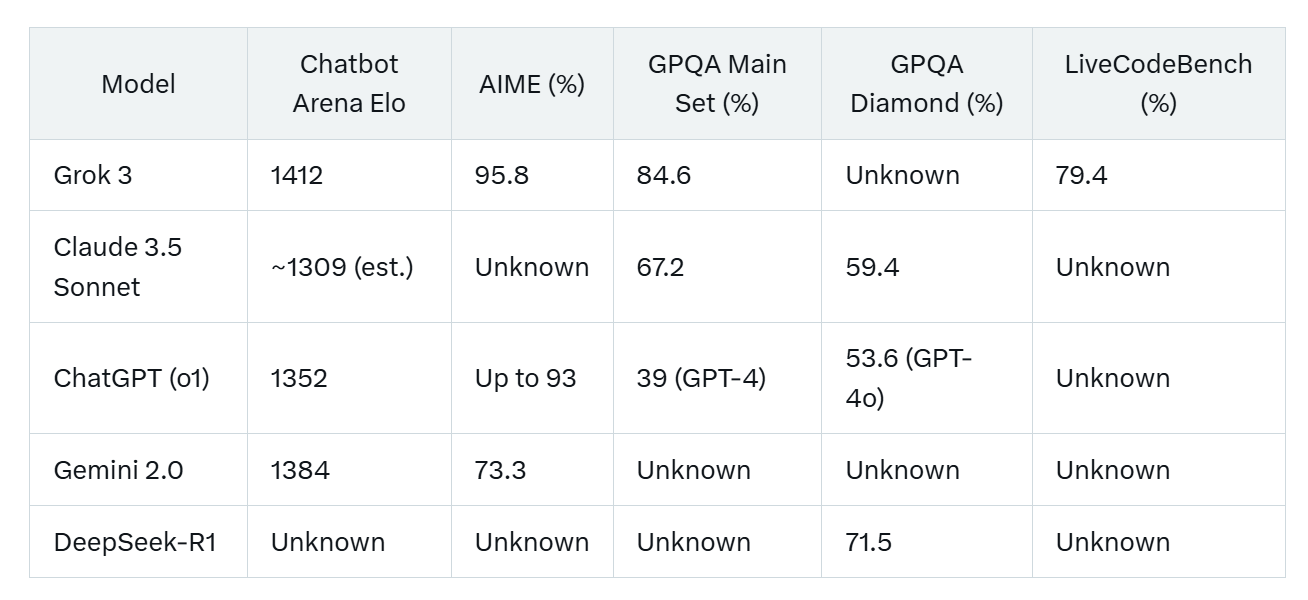
Note that some scores for DeepSeek and Gemini are incomplete due to limited public data, but trends clearly position Grok 3 as a benchmark leader in reasoning and technical tasks.
Capabilities and Features: Unique Strengths for Every Model
Each AI model brings distinct capabilities to the table, catering to different user needs:
Grok 3: Designed for “maximal truth-seeking,” Grok 3 features “Big Brain mode” for enhanced reasoning, multimodal capabilities (text and images), and real-time information via integration with X. It’s ideal for scientific and technical queries, aligning with xAI’s mission to understand the universe.
Claude: Anthropic’s Claude, particularly Claude 3.5 Sonnet, shines in ethical alignment, contextual comprehension, and complex reasoning over long dialogues. It’s perfect for customer service, data analysis, and formal writing, with a large 200,000-token context window and variants like Haiku, Sonnet, and Opus for various tasks.
ChatGPT: OpenAI’s ChatGPT, powered by models like GPT-4o and o1, is versatile for creative writing, general conversation, and problem-solving. Its o1 series excels in complex STEM reasoning, making it a go-to for diverse applications, though it may produce occasional inaccuracies or “hallucinations.”
Gemini: Google’s Gemini, especially Gemini 2.0, stands out for multimodal tasks (text, images, video) and integration with Google’s ecosystem. It offers features like Deep Research for comprehensive reports and is ideal for users within Google services, though it may lag in pure reasoning benchmarks.
DeepSeek: DeepSeek’s open-source models, like DeepSeek-R1, are cost-effective and strong in coding, technical reasoning, and Chinese NLP. It’s a niche player for developers and researchers, but its China-based origin raises security concerns, potentially limiting adoption in some regions.
An interesting twist? DeepSeek’s open-source approach contrasts with the proprietary nature of its competitors, offering a cost-effective alternative that could democratize AI development — though geopolitical tensions add complexity.
Cost and Accessibility: Balancing Performance and Price
Cost is a critical factor when choosing an AI model:
Grok 3: Requires a $40/month Premium+ subscription for full access, offering unlimited use without time limits. This higher price reflects its cutting-edge performance but may deter casual users.
Claude: Offers a free tier (Claude 2) and a $20/month Pro plan, providing 5x usage, priority access, and early features. It’s more affordable than Grok 3 but less powerful for advanced tasks.
ChatGPT: Features a free tier using GPT-3.5 Turbo, with ChatGPT+ at $20/month for GPT-4o access. Advanced models like o1-preview cost $15–$60 per million tokens, making heavy use pricier than Grok 3’s flat rate.
Gemini: Provides a free tier (Gemini 2.0 Flash) and Gemini Advanced at $19.99/month for enhanced capabilities. Costs are competitive but less transparent for heavy use compared to Grok 3’s fixed fee.
DeepSeek: Often free or low-cost for basic use, with competitive API pricing for developers. Its open-source nature makes it budget-friendly, but performance may not match Grok 3’s benchmarks.
DeepSeek’s free access is a standout advantage, especially for cost-conscious users, but it may sacrifice some performance compared to Grok 3’s dominance.
Use Cases and Recommendations: Finding Your Perfect AI Match
Each model excels in specific scenarios, so your choice depends on your needs:
Grok 3: Ideal for researchers, engineers, and users prioritizing cutting-edge reasoning, speed, and scientific/technical queries. Its high cost may limit casual use, but it’s the top pick for performance.
Claude: Best for businesses and users needing ethical, context-heavy tasks like customer service, data analysis, and formal writing. It’s a strong choice for those valuing alignment and nuance.
ChatGPT: Perfect for writers, general users, and creative professionals needing versatility in conversation, brainstorming, and problem-solving. It’s widely accessible but less dominant in reasoning benchmarks.
Gemini: Suited for users within Google’s ecosystem, such as educators and marketers, who need multimodal capabilities and fast responses. It’s less effective for pure reasoning compared to Grok 3.
DeepSeek: Optimized for developers and researchers focusing on coding, technical reasoning, and Chinese NLP. Its cost-effectiveness and open-source nature are appealing, but security concerns may restrict use in some regions.
An unexpected insight? DeepSeek’s potential to disrupt the AI market with its efficiency challenges Western models, despite geopolitical hurdles, making it a wildcard worth watching.
Conclusion: Who Reigns Supreme?
As of March 2025, Grok 3 appears to outshine Claude, ChatGPT, Gemini, and DeepSeek in raw benchmark performance, particularly in Chatbot Arena, GPQA, and LiveCodeBench. However, the “best” model depends on your specific needs. If you prioritize raw performance and truth-seeking, Grok 3 is the clear leader. For ethical alignment, choose Claude; for versatility, ChatGPT; for multimodal tasks, Gemini; and for cost-effective coding, DeepSeek.
The AI landscape is rapidly evolving, and each model brings unique strengths to the table. Whether you’re a researcher pushing scientific boundaries, a developer coding the next big app, or a business seeking ethical AI solutions, there’s a model for you. Stay tuned as these models continue to improve, and let us know in the comments which AI you’re using and why!
Sources